Summary
We propose a significantly more robust dense feature matcher than previous approaches.
Method
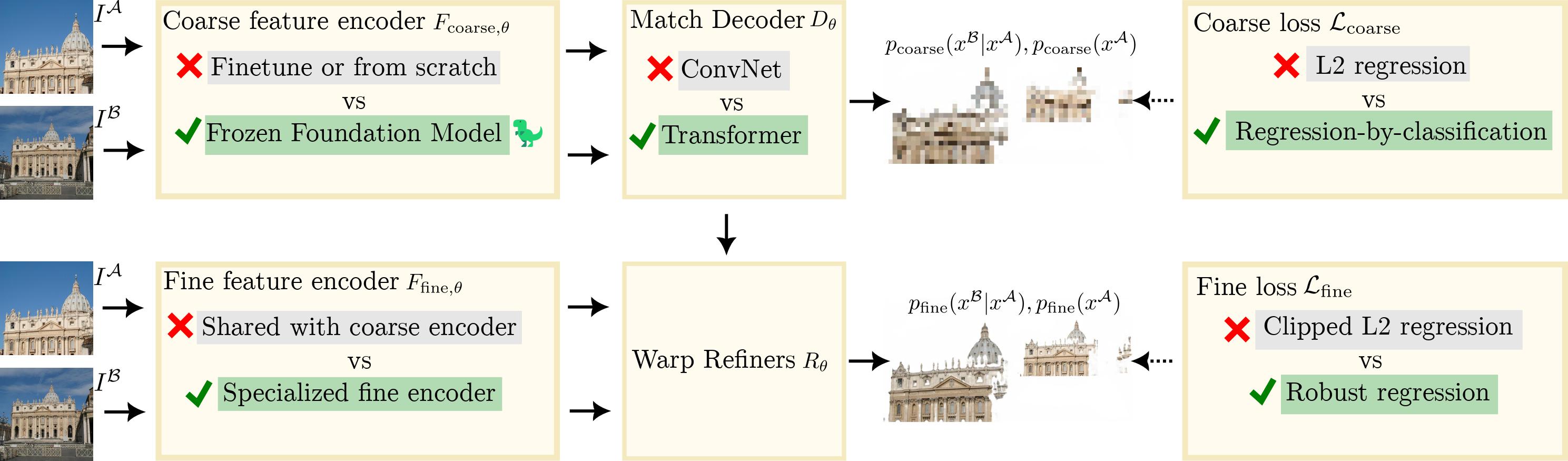
Our approach consists of four main contributions (see figure above):
- We use a foundation model (DINOv2) instead of training from scratch, leading to more robust matches.
- We use a specialized ConvNet for fine features.
- We propose a Transformer match decoder that predicts anchor probabilities instead of coordinate regression.
- We use better losses.
BibTeX
@article{edstedt2023roma,
title={{RoMa: Robust Dense Feature Matching}},
author={Edstedt, Johan and Sun, Qiyu and Bökman, Georg and Wadenbäck, Mårten and Felsberg, Michael},
journal={arXiv preprint arXiv:2305.15404},
year={2023}
}